Mindblown: a blog about philosophy.
-
@RequestParam, @QueryParam, @PathVariable & @PathParam
@RequestParam, @QueryParam und @PathVariable, PathParam werden verwendet um Werte aus dem Request auszulesen. Doch welchen verwendet man wofür?
-
Clean Code Cheat Sheet
Ein brauchbarer Cheat Sheet mit ein paar Leitsätzen rund um das Thema Clean Code
-
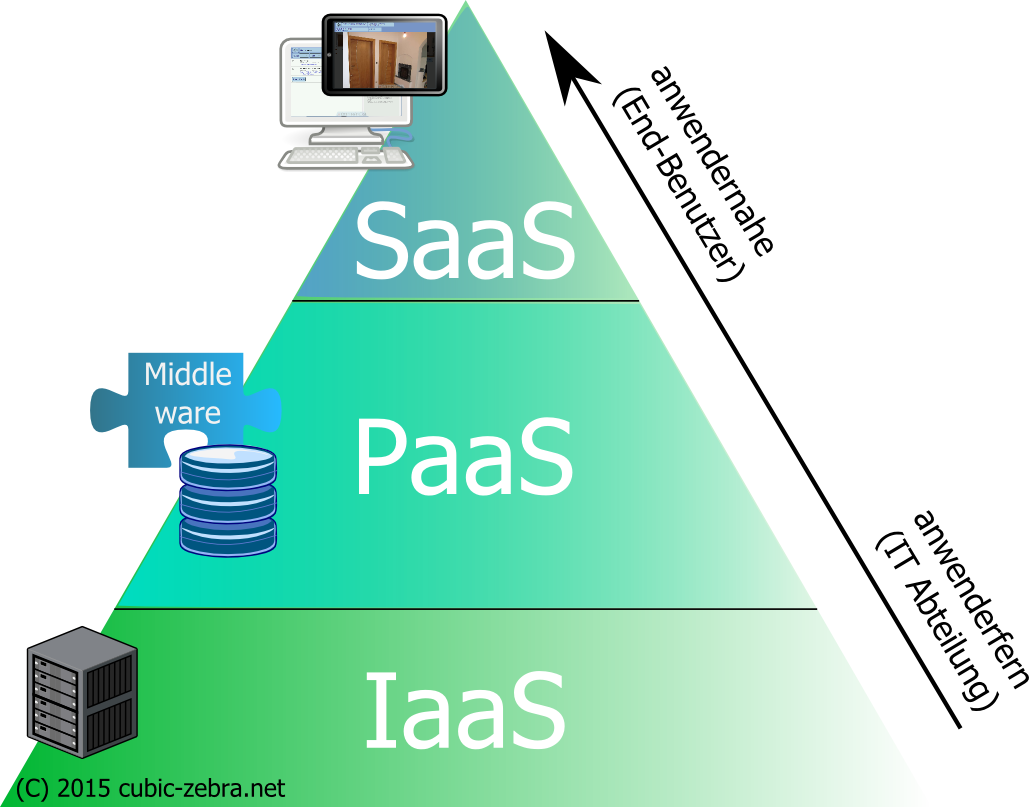
Teardown: Was steckt hinter einer Software-as-a-Service Lösung?
Dieser Artikel behandelt das Konzeptions-Thema für eine Software-as-a-Service Lösung anhand eines konkreten Beispiels. Er zeigt, welche Überlegungen hierbei zu bedenken sind und wie sie im betrachteten Fall gelöst wurden. Einleitung: Was ist SaaS? Was ist Software-as-a-Service (kurz SaaS) eigentlich? Der Begriff gehört zu der Gruppe XXX-as-a-Service wobei XXX üblicherweise für einen dieser 3 Begriffe steht:…
-

Mailserver SPF, DKIM, DMARC – Was wie und warum?
Domain-based Authentifizerung für Emails mit SPF, DKIM und DMARC Vorwort: Als Admininstrator von Servern stößt man immer wieder auf die Schlagwörter SPF, DKIM, DMARC. Da ich mich nun aufgrund eines aktuellen Projekts ebenfalls mit Email Versand und nicht-als-spam-markiert-werden beschäftigt habe möchte ich hier eine kleine Erklärung und Anleitung zu diesem Thema bereitstellen. Die Beispielkonfiguration in…
-
Jenkins – Manueller Neustart
HOWTO – wie man Jenkins manuell neustartet