Autor: Leo Eibler
-
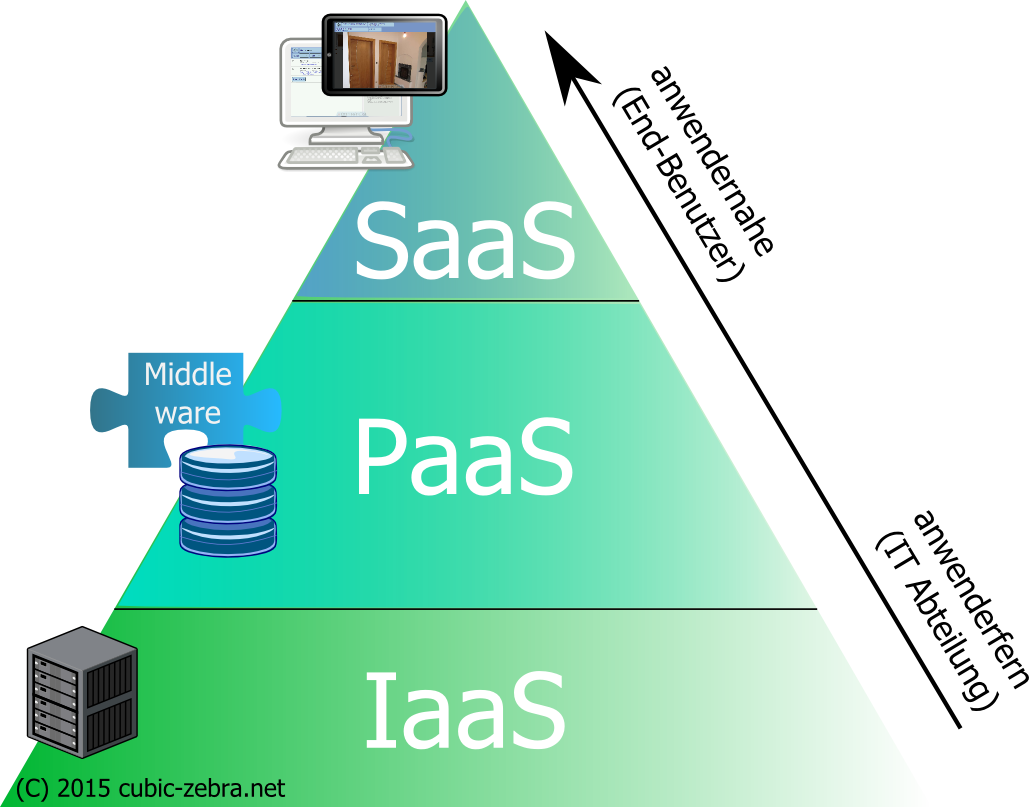
Teardown: Was steckt hinter einer Software-as-a-Service Lösung?
Dieser Artikel behandelt das Konzeptions-Thema für eine Software-as-a-Service Lösung anhand eines konkreten Beispiels. Er zeigt, welche Überlegungen hierbei zu bedenken sind und wie sie im betrachteten Fall gelöst wurden. Einleitung: Was ist SaaS? Was ist Software-as-a-Service (kurz SaaS) eigentlich? Der Begriff gehört zu der Gruppe XXX-as-a-Service wobei XXX üblicherweise für einen dieser 3 Begriffe steht:…
-

Mailserver SPF, DKIM, DMARC – Was wie und warum?
Domain-based Authentifizerung für Emails mit SPF, DKIM und DMARC Vorwort: Als Admininstrator von Servern stößt man immer wieder auf die Schlagwörter SPF, DKIM, DMARC. Da ich mich nun aufgrund eines aktuellen Projekts ebenfalls mit Email Versand und nicht-als-spam-markiert-werden beschäftigt habe möchte ich hier eine kleine Erklärung und Anleitung zu diesem Thema bereitstellen. Die Beispielkonfiguration in…
-
Mit Bash prüfen ob das eigene Script gerade läuft
Die Problemstellung Ein Script soll alle x Minuten laufen und eine bestimmte Tätigkeit auf dem Server ausführen. Nun kann es vorkommen, dass das Script aber länger braucht als die Zeitspanne bis zum nächsten Aufruf desselben Scripts (z.B. Kopier und Backup Jobs, Mails abholen, …) Natürlich sollte so ein Script dann nicht ein 2tes Mal gestartet…
-
Mehrsprachigkeit WordPress Plugins
Aus aktuellem Anlass (Erstellung meines ersten WordPress Plugins GarageSale) habe ich mich auch mit dem Thema Multilingualität und Übersetzungen auseinandergesetzt (Jetzt weiß ich auch woher I18N kommt – 18 Buchstaben zwischen i und n im Wort internationalization ;-) Grundsätzlich muss die zu übersetzende WordPress Komponente natürlich die Funktionen __(„text“,“domain“) oder _e(„text“,“domain“) verwenden. Siehe hierzu I18N…
-
pfSense 2.0 virtuelle IP Adressen
In der neuesten pfSense Release (Version 2.0) gibt es endlich eine Unterstützung um virtuelle IP Adressen (VIPs) direkt in der GUI anzulegen. Jedoch ist dies nicht ganz so einfach wie es auf den ersten Blick scheint. Grundsätzlich ist einmal zu unterscheiden ob man eine zusätzliche WAN oder LAN IP Adresse anlegen will. Zusätzliche WAN IP…